A Look at Building Software

Intro
Software is eating the world.
While you've likely heard this countless times, most people have little idea how software is developed and how a modern application is built. They may use a SaaS-based tool, but where did that tool/application come from? Most know that there is code running behind the scenes that some software engineers wrote that enables the website/application, but that’s the tip of the iceberg. Many different technologies allow this code to go from a programmer’s computer, to a person’s device, through an internet connection, and delivered continuously and without interruption. This post will help walk through how applications are developed and how the underlying technology that makes them possible works. The goal is to broadly show how applications are built, starting with the code and ending with the deployment, how the modern applications we take for granted come into existence.
For this blog, we built a straightforward toy application. Quickly interact with it, and then we will show what went into making the application and allowing one the ability to access it.
The Code
When we start writing software, we typically choose a programming language as the first step. We then use this and/or multiple languages to encode business logic (e.g., what should happen when a user selects an item from a dropdown) onto a computer. At its core, software is just encoded business logic. There are many available programming languages out there to choose from, but our example application uses mostly Python.
People understand that underlying software is code. What they likely don’t realize is the workflow and tooling that goes into that software. Even though our application is rather simple, it will be enough to show a decent chunk of the software development cycle. All the applications does is ask the user to click a button. When the button clicks, it should return the user's location based on their IP address. Note: this is just standard information that is sent from one’s browser to a website when they interact with a site. It is just capturing HTTP_X_FORWARDED_FOR for those interested.
To make programming more efficient, programmers use what is known as an Interactive Development Environment (IDE). IDEs have a bunch of helpful features, such as autocomplete, that speed up the code writing process. So, we code up the website in the IDE:

And boom! We have built a website. Now, all this was built on my laptop and is not actually deployed to the internet. However, we can use our computer to see if it will run locally.

In this gif, the site runs on my local server and port: http://127.0.0.1:5000/ and is only accessible to me. This is great for user testing before new code is released. One’s local computer is typically where code is first written and tested. Eventually, we will deploy this to be accessible to anyone with an internet connection and walk through how that happens.
First, we bring in another developer to help write some of this code. I can't be expected to manage this button myself. So, we bring on Nick. With Nick onboarded, we have multiple people working on the same codebase. We will want a way to manage two people working on the same code, much like when numerous people are working on the same document, they might use Google Docs. To do this, we will use a software called Git. And to make sure everyone can download the code, we will host it on GitHub or Gitlab, the two most popular hosting solutions which allow everyone accesses to the same source code.
Git goes hand in hand with writing code and is a critical piece of building software, especially when building software with a team.
Git and Repositories
Git is open-source software for managing software development via source control. It tracks all changes that happen across all files in a codebase. This is important because it makes it much easier for teams of software engineers to work together. Typically, if you build software, there will be a main branch with the "gold" standard code. This code runs the application and is known as the main branch. If I am working on a new feature, I will create a branch off the main branch to build out the new feature. Another engineer would also work on a separate branch for a different feature. Once these features are ready to be integrated, they get merged back into the main.

Anyone who has worked on a word/ppt document can think of this as a much more efficient way of managing changes. Instead of "doc_v1", "doc_v2", "doc_v3”, or better yet, "DOC Your Initials,” the software keeps track of the changes throughout time and automatically shows the differences. This allows you to go back to a previous point in time i.e. you can go back to the codebase before an error was introduced and start from that point.
So, it starts with the main. I do some work, someone else does some work, and eventually, we add this work to the main repository. That is how new code gets integrated into the software and thus our application. This is done because you want to be able to build and test new code without worrying about it messing up your current, well-running application. It also allows whoever manages the main branch to review the code before accepting it into the software. One change in software can have catastrophic effects on the rest of the software, so better to do that off to the side.
Here is an example of a commit for our application where Nick, working on his branch, wants to make some changes to the codebase. The commits are simple. He changes the text on the button and adds a gif. We review the code changes below, and they look good, so we merge his code into the main code branch. Afterall, gifs make everything more fun.
Change 1

Change 2

You can see what was changed and what was added based on the highlights above. Hopefully, this shows how helpful git and the UI-based sitting on top of git can be!
Now when we run the site locally, we see the new Gif!

We currently have a working site with two collaborators. As the site grows in complexity, we will want to ensure it works properly, since we’d rather not shift through every page on a site locally every time, we make a change. This is where testing and continuous integration come in. The writing of code to test the code!
Testing and Continuous integration
To help ensure the quality of the software, checks are written that test that the code is working correctly. These tests are typically automated and run every time new software is deployed. This helps ensure that the code changes being merged won’t cause any unforeseen issues.
For example, suppose we had a function called add that took two numbers and added them say
add(x, y) = x + y
We could write a test:
add(2, 10) = 12
Every time I add new code to my repository, add(2, 10) is run to ensure it still equals 12. If someone changed this function to be add(x, y) = x – y, the test would fail, and the latest version of the code would fail to deploy. That is continuous integration, which is a critical component handled before code deployment. Now that we have code, collaboration capabilities, and good tests, we are almost ready to deploy this code as software for users to interact with. But first we need to setup the proper infrastructure.
Infrastructure
Our app is a website, so we want anyone with internet to be able to access our app. To do this, we need to ensure it can handle all these requests and scale with web traffic. This is where cloud-based infrastructure comes into play. There are three leading cloud providers: Google, Microsoft, and Amazon. For our examples, we will use AWS. An important concept with releasing code is making sure it scales and can handle all the requests sent to it. Just think about how many people visit Google every day. We don’t need to meet those requirements, but it should be able to handle some decent traffic. Luckily, that is where load balancers and autoscaling come in.
Load Balancing and Autoscaling
When you log onto a website, it is most likely using some sort of load balancing. That means that there is some software sitting between you, the user (client), and the server that acts like an air traffic controller, determining what computer to send that request to based on the utilization of other computers. Much like an air traffic controller telling a plane what runway to land on. So, when you type in "expedia.com," behind the scenes, you get sent to different computers based on variables. A visual and an example might be helpful here:

A few things are happening here:
The request gets sent to the load balancer
The load balancer routes this request to the computer (EC2)
The EC2 then serves the user the response
You can see this concept in action at the following site: Link (or watch the video below). Keep hitting refresh (ctrl + r), and you'll notice the hostname changing. That means that the response is coming back from a separate computer.

These are all virtual computers in AWS cloud that share space (multitenancy) with other applications, but we can ignore all that for now.
Even more sophisticated with these computers is that they expand and contract as the need for computing increases and decreases. To bring this back to the air traffic control metaphor, if you've ever taxied in the air on a plane, typically, there wasn’t a runway available for landing. Modern applications can add a runway and take away runways depending on the number of planes requesting to land – wouldn’t that be nice – no taxing in the air again! Fewer users on a Tuesday means less computers and less money spent! This process of new computers getting spun up to handle more users accessing our website is known as autoscaling.
The same thing that we see in the gif above will be happening with our button app; we won't be able to tell what computer from Amazon is serving the request. But that is the point: we want to request a site, and it will always comes back with a response.
Build Once, Deploy Anywhere!
What we didn’t describe above is that each of the computers that get magically spun up for us has the same underlying code running on it. This ensures the same application is running everywhere. The same code is downloaded onto each computer running in Amazon’s cloud. It looks something like below.
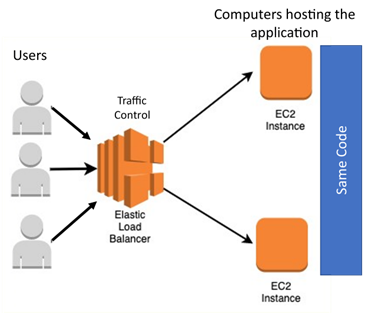
In our button example, all we did was upload a zip file to amazon with our code that tells the computer what software to install - our code - to ensure it runs properly. There are many ways to do this, but the important thing is that each computer is given the same instructions on properly setting up the application.
Finally, we should quickly touch on DBs even if our application doesn’t use a database.
The Database (DB)
Since we showed an app that is so simple, we didn’t need a DB, but every application will have a one that an application relies on for data. When you log into a website with a username and password, data gets sent from the computer hosted somewhere else - in our case, AWS - to a database to verify if you should be allowed to enter the site. You can see this interaction in the image above, where the EC2 Instance, which is just a computer, sends information to a database to get data back. And typically, data that is rendered on a webpage is served via a database of some kind.
So, the final, simple application might look something like the following:

Summary
At the heart of each of these different steps is helping the software scale whether through efficiency gains (IDE), collaboration (Git), or infrastructure (AWS). And the great thing that I hope you noticed is that most of the services provided above are provided by AWS or a cloud provider. They manage the different infrastructure pieces to help the software scale.
There is plenty that we did not touch on here: Kubernetes, Docker, routing, message queuing, security, availability, caches, Jira, and other pieces that are standard within modern software development. But I do think there is enough here for one to start getting a better grasp on how software is developed, deployed, and delivered, even if this is a significantly less complex than your standard application. At a minimum, one can see how much more goes into building software than just code!
Finally, registering the site and running the computers on AWS cost me about $16, so you can quickly see why the cloud providers are so valuable.